


Parameter wie Temperature und Top-P in ChatGPT und OpenAI Playground
Keine Artikel mehr verpassen? Jetzt Newsletter abonnieren »
In diesem Artikel möchte ich dir die unterschiedlichen Parameter vorstellen, die du im OpenAI Playground findest, die du aber auch für andere Large Language Modelle (LLMs), wie Gemini oder Mistral verwenden kannst. Ich möchte darstellen, wie du Parameter wie die Temperature, Top-P oder Presence Penalty bei der Erstellung von Texten, beim Arbeiten mit Daten oder der Entwicklung von Marketing-Strategien verwenden kannst.
- Definition: Was sind Parameter?
- OpenAI-Parameter: Zwischen Temperature, Top-P und Presence Penalty
- Detail: Die Parameter im Details
- Anwendungen: Die Anwendung von Parametern für bessere Ergebnisse
- LLMs: In welchen anderen LLMs findet man diese Parameter noch
- ChatGPT: Kann man Parameter in ChatGPT anwenden?
- Ressourcen: Weitere Ressourcen und Links zu Parameter in OpenAI & Co.
Was sind Parameter von OpenAI & Co.?
Unter Prompt-Engineering verstehen viele die Formulierung guter und relevanter Prompts. Oft übersieht man aber, das es neben der Verwendung von Rollen, Instruktionen oder Methoden, wie Few-Shot-Prompting oder Chain-of-Thought Prompting, starke Werkzeuge gibt, wie die Verwendung von Parametern. Das sind im einzelnen:
- die Temperature, welche die „Zufälligkeit“ steuert,
- Top-P, der die Diversität der Wörter steuert,
- die Frequency Penalty, welches das „Wiederholungen von Wörtern“ steuert und
- die Presence Penalty, das die „Wiederholung von Konzepten“ beeinflusst.
Diese Parameter kannst du aber nur sehen, wenn du in den OpenAI Playground gehst, ein Projekt bei Google (Vertex) anlegst oder z.B. den Aleph Alpha Playground verwendest. Wir schauen uns mal die Parameter im Einzelnen an. Der Einfachheit halber werde ich mich jetzt auf den OpenAI Playground fokussieren, meine aber auch andere LLMs damit.
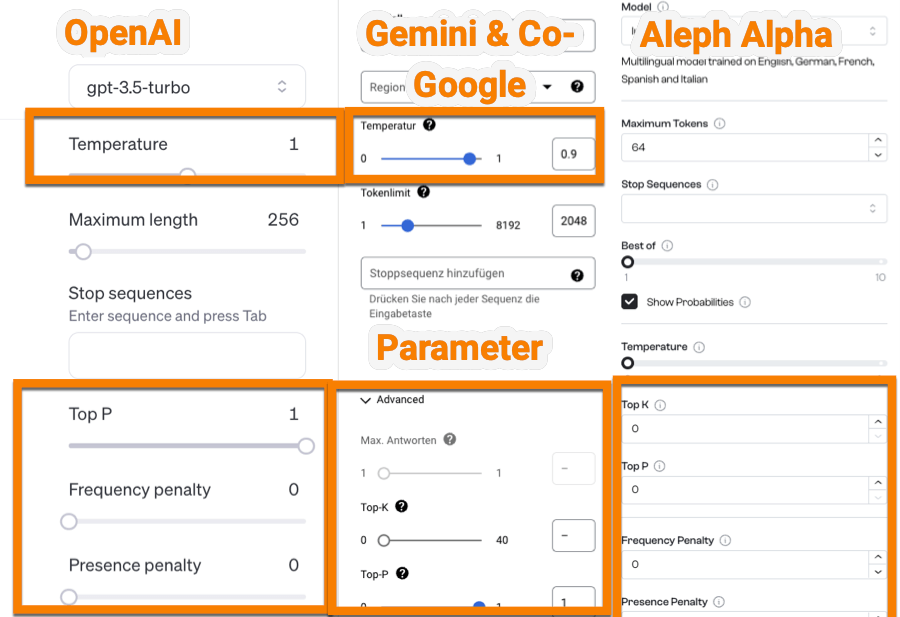
Was sind wichtige Parameter im OpenAI Playground?
Es gibt im Playground von OpenAI, aber auch in den anderen LLM-Tools, wichtige Parameter, die dir helfen die richtigen Einstellungen für deine Chats zu wählen.
Wichtige ChatGPT-Parameter
Hier sind einige gängige Parameter, die du im Playground, aber auch über die OpenAI-API ansprechen kannst:
- Maximale Tokens: Legt die maximale Länge für die Ausgabe der Tokens fest. Die maximale Länge hängt dann von deinem gewählten Modell ab. Das gewählte Modell kann z.B. GPT-4, GPT-3.5 oder auch Anthropic sein.
- Temperature: Steuert die Zufälligkeit der Outputs.
- Top P (Nukleus Sampling): Bestimmt die Vielfalt der Antworten, indem nur die obersten „P“ Prozent der wahrscheinlichen Wörter berücksichtigt werden.
- Frequency-Penalty: Die Frequency-Penalty reduziert Wiederholungen, indem die Wahrscheinlichkeit von häufig verwendeten Wörtern verringert wird.
- Presence-Penalty: Fördert die Einführung neuer Themen/Konzepte in deine Chats.
Ich möchte mich hier auf die wesentlichen Parameter beschränken und dir im Detail zeigen, was Temperature und Top-P mit deinen Chats bewirken. Hilfreiche Tools & Ressourcen sind:
- OpenAI-Playground
- Tokenizer von OpenAI
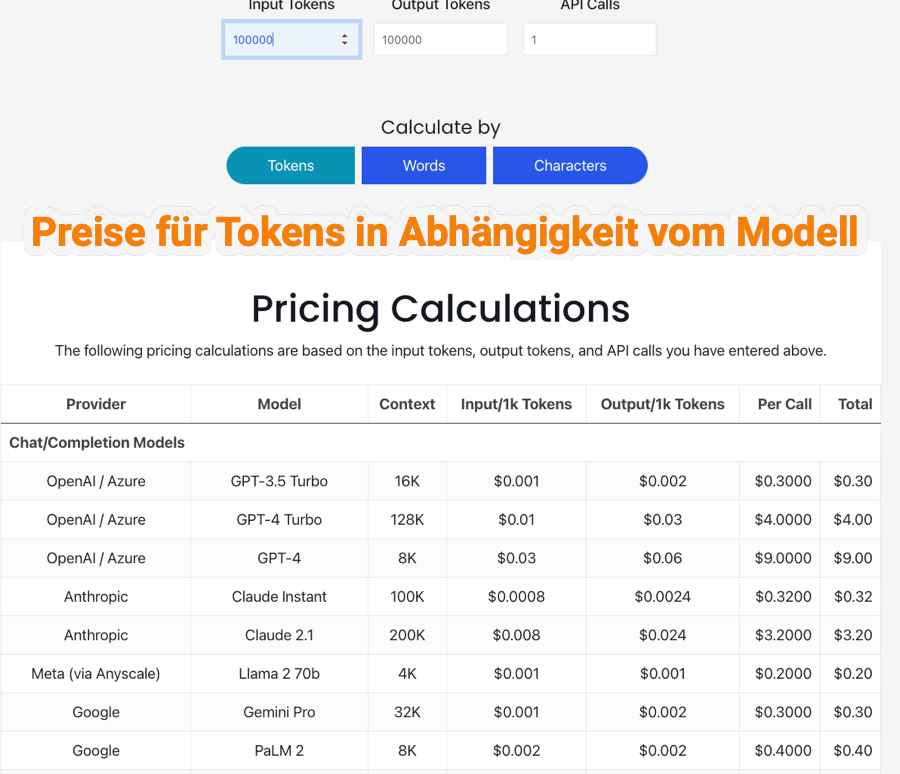
- Pro-Tipp: Hier gibt es ein Kalkulationstool für Tokens 8
- hier kannst du, wenn du ein Konto im Playground hast, einen API-Key generieren
- Übersicht der verschiedenen GPT-Modelle und den Limitierung der Tokens
- erweiterte Übersicht der Modelle (GPT und Anthropic) mit ihren jeweiligen Tokenbegrenzungen (Context-Window)
Was sind Tokens im OpenAI Playground?
Token kann man sich als Teile von Wörtern vorstellen. So wie wir Menschen Silben verwenden, werden hier Wörter in einzelne Bestandteile (Tokens) zerlegt. Konkret bedeutet, das wenn ein Tool wie ChatGPT deinen Input verarbeitet, wird die Eingabe in einzelne Token zerlegt. Um sich das besser vorzustellen zu können gehe doch mal in den Tokenizer von OpenAI und gib z.B. einen Text von deiner Seite ein. Ich habe ein Zitat von Stephen Hawking genutzt „I have noticed that even people who claim everything is predetermined and that we can do nothing to change it, look before they cross the road“ und das in Deutsch und Englisch. Man sieht hier sehr gut : 
Das Zitat hat im Deutschen
- Worte: 28
- Token 55
- Zeichen: 195
Das Zitat hat im Englischen
- Worte: 28
- Token 31
- Zeichen: 159
Man sieht mit diesem einfachen Beispiel, das es hier je nach Sprache durchaus Unterschiede gibt.
- 1 Token ~= 4 Zeichen im Englischen / 2 Zeichen im Deutschen
- 100 Token ~= 75 Wörter im Englischen / 50 Worte
Das ist jetzt nur einmal ganz grob, aber man sieht Unterschiede. Warum ist das wichtig?
Die Anzahl der maximalen Tokens als Parameter in LLMs legt die maximale Länge der Ausgabe des Modells fest. Gleichzeitig sind die Tokens auch wichtig in Bezug auf das Context-Window der jeweiligen Modelle. Mehr dazu bei TechTarget oder bei Medium (sehr ausführlich).
Wann passt man die maximale Länge der Tokens in OpenAI & Co. an?
Maximize: Für längere und ausführlichere Antworten.
Reduce: Verringere die maximale Länge für kurze und prägnante Antworten.
Use-Cases: Längere Antworten für z.B. Storytelling oder holistische Inhalte in der SEO, weniger Tokens für schnelle Antworten oder auch zum Testen, da mindestens im OpenAI Playground und über die API viele LLMs auf Basis von verbrauchten Tokens abrechnen. Siehe hier mal im folgenden Bild:
Was bedeutet der Parameter Temperature bei OpenAI?
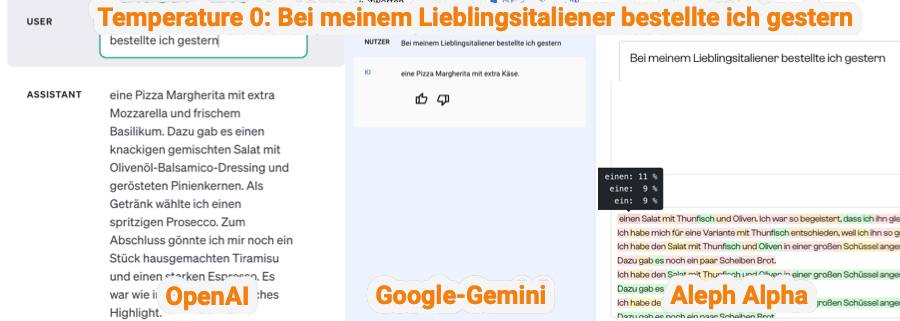
Definition Temperature bei LLMs: Mit der Temperature kannst du im OpenAI Playground den Grad der Zufälligkeit des nächsten Tokens bestimmen. Wenn wir vereinfacht jetzt von der Zufälligkeit des nächsten Wortes reden, können wir mit einer niedrigen Temperatur steuern wie vorbestimmt oder kreativ das Sprachmodell (z.B. GPT-4) agieren soll. Die Einstellungen der Temperatur reichen von O bis 2 bei OpenAI und bei Google und Aleph Alpha von 0 – 1.
- niedrige Temperature: Eine niedrige Temperature macht den Text vorhersagbar und konsistent. Bei einer Temperature von 0 wird immer das nächstwahrscheinliche Wort (Token) gewählt. Eine niedrige Temperature eignet sich besonders für Antworten, wo du Wert auf Präzision bzw. wahre und richtige Antworten legst. Das können Anwendungen sein, wie das Arbeiten mit Daten, das Generieren von Code oder konservatives Texten sein.
- hohe Temperature: Ein hohe Temperature führt zu kreativen und ggf. auch unerwartbaren Ergebnissen, bei Werten über ca. 1,3 kann es auch sein, das nur noch Unsinn erzeugt wird.
Die Temperature kann nicht in ChatGPT verwendet werden, aber du kannst die Logik hinter den Parameter-Einstellungen über deinen Prompt definieren.
Beispiele für die Sprachwahl, wenn du eine „geringe Temperature“ brauchst:
- Was sind Best-Practices…?
- Was sind bewährte Schritte zur Analyse von..?
- Sei präzise und halte dich immer an Fakten.
Beispiele für die Sprachwahl , wenn du eine „hohe Temperature“ brauchst:
- Erstelle einen kreativen Text zu [Thema]…
- Entwickle einen unkonventionellen Ansatz.
- Nutze einen kreativen und ungewöhnlichen Ansatz.
Was bedeutet der Parameter Top-P bei OpenAI?
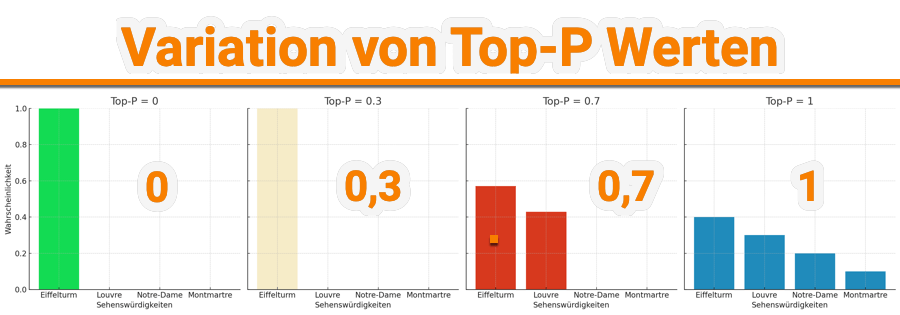
Definition: Der Top-P-Wert (Nukleus-Sampling) bestimmt, wie das LLM die Vielfalt seiner Antworten steuert. Beim Top-P-Sampling werden nicht alle folgenden Wörter (Token) berücksichtigt, sondern das nächste Wort (Token) wird aus einer kleineren Menge von Wörtern ausgewählt, die zusammen eine kumulative Wahrscheinlichkeit über dem Top-P-Wert haben. Der Top-P Wert ist zwischen 0-1 darstellbar. Dabei bedeutet 0 -> 0% und 1 -> 100%
Top-P = 0,5: Dies bedeutet, dass nur die Wörter in Betracht gezogen werden, die zusammen mindestens 50% der gesamten Wahrscheinlichkeit darstellen, während weniger wahrscheinliche Optionen verworfen werden. Dadurch bleibt eine angemessene Bandbreite an möglichen Antworten erhalten. Ich zeige dir ein Beispiel, um das besser darzustellen:
Beispiel: Angenommen, wir haben eine Situation, in der ein Sprachmodell, die nächste Sehenswürdigkeit in Paris vorschlagen soll, die man als Tourist besuchen könnte. Du hast eine Liste möglicher Sehenswürdigkeiten (A, B, C, D) mit zugehörigen Wahrscheinlichkeiten, basierend darauf, wie relevant oder populär sie sind:
- Wort A (Eiffelturm) – 40%
- Wort B (Louvre) – 30%
- Wort C (Notre-Dame) – 20%
- Wort D (Montmartre) – 10%
Wir setzen den Top-P im OpenAI Playground auf 0,9 (90%). Dies bedeutet, dass wir eine kumulative Wahrscheinlichkeit von bis zu 90% der möglichen nächsten Sehenswürdigkeiten in Paris festlegen. Die Berechnung kann dann wie folgt aussehen: Die Wahrscheinlichkeiten werden solange addiert bis wir den Top-P-Wert erreicht oder überschritten haben.
- Schritt 1: Kumulative Wahrscheinlichkeit nach Hinzufügen von Wort A (Eiffelturm): 40%
- Schritt 2: Kumulative Wahrscheinlichkeit nach Hinzufügen von Wort B (Louvre): 40% + 30% = 70%
- Schritt 3: Kumulative Wahrscheinlichkeit nach Hinzufügen von Wort C (Notre-Dame): 70% + 20% = 90%
Beim dritten Schritt erreichst du jetzt den Top-P Wert von 0,9 also 90% mit den Wörtern A, B und C.
Auswahl basierend auf Top-P: Aufgrund der Top-P-Einstellung von 0,9 werden Eiffelturm, Louvre und Notre-Dame als mögliche nächste Wörter (Sehenswürdigkeiten) in Betracht gezogen. Der Montmartre würde ignoriert, da das Hinzufügen dieser Option die kumulative Wahrscheinlichkeit über 90% treiben würde. Im Ergebnis bedeutet das: Das Modell würde zufällig eine der Sehenswürdigkeiten Eiffelturm, Louvre oder Notre-Dame vorschlagen, aber den Montmartre auslassen. Diese Einstellung würde eine vielfältigere Auswahl von Wörtern, aber innerhalb gesetzter (sinnvoller) Grenzen festlegen. Hier siehst du eine Visualisierung der verschiedenen Top-P Einstellungen:
Kann man Temperature und Top-P kombinieren?
Was passiert eigentlich, wenn man die Parameter miteinander kombiniert? Noch einmal kurz zur Wiederholung:
- Temperature: Eine höhere Temperature führt zu einer gleichmäßigeren Verteilung über die verschiedenen Sehenswürdigkeiten, was mehr Vielfalt in den generierten Texten ermöglicht
- Top-P: Ein niedriger Top-P-Wert konzentriert die Auswahl auf die wahrscheinlichsten Optionen, während ein höherer Top-P-Wert mehr Vielfalt zulässt, indem er die kumulative Wahrscheinlichkeit auf eine größere Anzahl von Optionen verteilt.
Zum besseren Verständnis zeige ich dir jetzt noch einmal das Beispiel mit den Sehenswürdigkeiten in Paris und mit den ursprünglichen Wahrscheinlichkeiten von
- Wort A (Eiffelturm) – 40%
- Wort B (Louvre) – 30%
- Wort C (Notre-Dame) – 20%
- Wort D (Montmartre) – 10%
Wir verwenden jetzt verschiedene Werte für die Einstellung Temperature. In der folgenden Tabelle siehst du, wie sich die verschiedenen Wahrscheinlichkeiten durch die Anwendung von Temperature verändern. Die Berechnungen habe ich mit ChatGPT gemacht.
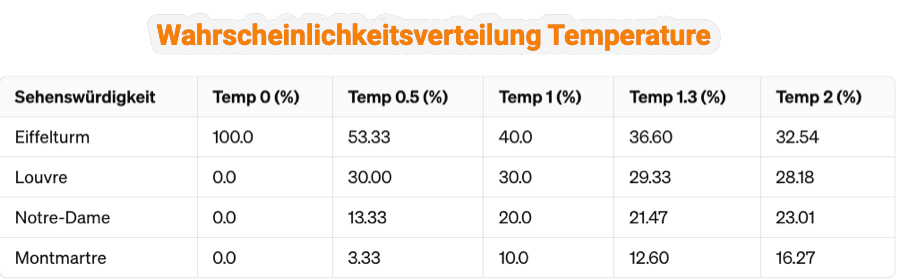
Was heißt das jetzt?: Durch die Temperature glättet sich die Wahrscheinlichkeitsverteilung und wie man hier bei einer Temperature von 2 sieht, steigt die Sehenswürdigkeit Montmatre von 0% auf 16,27%.
Hintergrund: Was passiert jetzt mit der Veränderung der Temperature in verschiedenen Szenarien? Zur Berechnung wird hier die Softmax-Funktion verwendet und über die Temperature das „Chaos“ gesteuert. Wer daran Interesse hat, kann bei Kasim Te oder Wikipedia mehr nachlesen.
Wie können jetzt verschiedene Szenerien aussehen?
Niedrige Temperatur (0,5) mit hohem Top-P: Hier erhältst du Texte, die sowohl logisch als auch reich an Vielfalt sind. Diese Kombination passt gut für Inhalte, bei denen es auf Genauigkeit und Verständlichkeit ankommt, aber dennoch eine gewisse Originalität und ein breites Spektrum an Ausdrücken aufweisen. Diese Einstellung stellt eine Balance zwischen Präzision und Kreativität dar. Gute Einsatzmöglichkeiten sind hier zum Beispiel bei Bildungsmaterialien, Fachartikeln oder sogar in anspruchsvollen Geschäftsdokumenten. Ich habe jetzt mal verschiedenen Einstellungen in einer Matrix simuliert, damit du besser verstehst, wie du Temperature und Top-P in ChatGPT über Worte verwenden könntest.
| Temperatur
/ Top-P
|
Top-P 0.3 | Top-P 0.7 | Top-P 1.0 |
|---|---|---|---|
| Temperatur 0.5 | Schreibe einen kurzen und prägnanten Überblick über ein neues Smartphone, fokussiere auf die meist gefragten Features. | Beschreibe ein neues Smartphone mit seinen Schlüsselfunktionen und hebe ein paar weniger bekannte, aber interessante Features hervor. | Erstelle einen umfassenden Guide zum neuen Smartphone, der alle Features und mögliche Nutzungsszenarien abdeckt. |
| Temperatur 1.0 | Schreibe eine kreative Einführung für ein neues Smartphone, konzentriere dich dabei auf die innovativsten Features. | Entwickle eine lebhafte und vielseitige Präsentation eines neuen Smartphones, die sowohl die Hauptfunktionen als auch versteckte Perlen beinhaltet. | Erzähle eine fesselnde Geschichte über das Leben, das mit dem neuen Smartphone möglich wird, einschließlich aller denkbaren Features und Anwendungen. |
| Temperatur 1.3 | Denk ganz frei und wage einen futuristischen Blick auf ein neues Smartphone, fokussiere dich auf ein oder zwei ungewöhnliche Features, die es von allem bisher Dagewesenen abheben. | Entwerfe einen visionären und breit gefächerten Text über ein neues Smartphone, der unkonventionelle Features und Nutzungsideen umfasst. | Erschaffe eine fantasievolle und grenzüberschreitende Geschichte, die zeigt, wie ein neues Smartphone die Welt verändern könnte, ohne Einschränkungen bei den Features oder dem Einsatzbereich. |
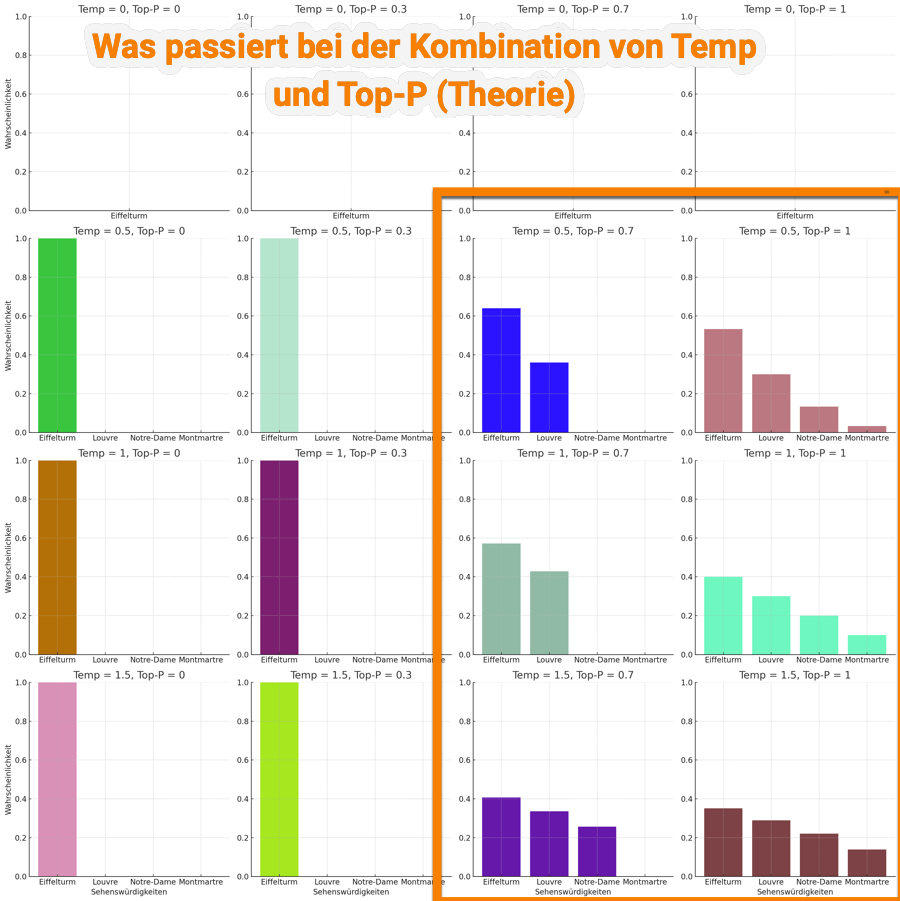
Du hast Interesse an Mathematik? Dann interessiert dich das folgende Bild mit den verschiedenen Möglichkeiten von Temperature und Top-P kombiniert. Du siehst hier relativ schnell, dass einige Kombinationen keinen großen Sinn machen. Deswegen habe ich in der oberen Tabelle nur Kombinationen gewählt, die auch im Prompting Sinn machen können.
Welche weiteren Parameter gibt es?
Definition: Die Presence Penalty ist ein weiterer Parameter im OpenAI Playground und beeinflusst, wie neue Ideen oder Konzepte in dem Output eingeführt werden. Ein hoher Wert beeinflußt, ob bereits angesprochene Themen weniger wahrscheinlich eingeführt werden. Ziel der Presence Penalty:
- niedrige Presence Penalty: Führt zu „konservativeren“ Ergebnissen
- hohe Presence Penalty: Führt zu kreativeren Lösungen
Wie kombiniert man Top-P mit der Presence Penalty?
Nur kurz noch einmal als Wiederholung:
Presence Penalty führt zu Reduzierung von Wiederholungen: Durch das Einstellen einer Presence Penalty verringerst du die Wahrscheinlichkeit von Wörtern oder Phrasen, die bereits in deinem Text vorkamen. Dies hilft dir, Wiederholungen zu minimieren und die Einzigartigkeit deines Inhalts zu steigern. Je höher du die Penalty setzt, desto mehr neigt das Modell dazu, neue und unterschiedliche Konzepte oder Vokabular einzuführen.
Wie sieht eine kombinierte Anwendung aus?
Top-P – Steuerung der Wahrscheinlichkeitsverteilung: Wenn du Top-P anwendest, begrenzt du die Auswahlmöglichkeiten für das nächste Wort oder die nächste Phrase auf einen bestimmten Prozentsatz der höchsten Wahrscheinlichkeiten. Das bedeutet, du schließt weniger wahrscheinliche und potenziell unzusammenhängende Optionen aus, wodurch die Kohärenz und Relevanz in deinem generierten Text gefördert wird. Gleichzeitig lässt du eine gewisse Variabilität und Kreativität zu. Im Ergebnis führt das dann zu
- erhöhter Textdiversität ohne Qualitätseinbußen: Wenn du beide Methoden kombinierst, erreichst du ein Gleichgewicht zwischen Logik und Kohärenz (durch Top-P) und Originalität bzw. Vielfalt (durch Presence Penalty). Das ermöglicht es dir, thematisch fokussiert und kohärent zu bleiben, während du gleichzeitig Redundanz vermeidest und frische, vielfältige Inhalte generierst.
- Adaption: Durch die Feinabstimmung beider Parameter kannst du die Textgenerierung flexibel an unterschiedliche Anwendungsfälle anpassen. Für kreatives Schreiben oder Anwendungen, bei denen Originalität im Vordergrund steht, kann eine höhere Presence Penalty sinnvoll sein. Für Aufgaben, bei denen es auf Präzision und thematische Enge ankommt, hilft dir eine genaue Einstellung von Top-P, die Balance zu halten.
Mit dieser Kombination hast du die Möglichkeit, deine Texte so zu steuern, dass sie sowohl thematisch kohärent als auch reich an neuen Ideen und Ausdrucksweisen sind. Das ist besonders wertvoll für anspruchsvolle Anwendungen wie gute und tiefgreifende Ratgeber-Inhalte oder journalistische Inhalte
Fazit zu Temperature, Top-P & Co.
Die „Temperature“, „Top-P“ und „Presence Penalty“ sind wichtige Parameter, die du in OpenAI Modelle wie GPT-4 verwenden kannst um die „Wahrscheinlichkeiten“ der Ausgabe zu steuern. Auch wenn du die Parameter nur im Playground der einzelnen Anbieter verwenden kannst und nicht in ChatGPT, kann die Logik dahinter dir helfen deine Prompts deutlich besser zu machen. Weitere interessante Informationen zu besseren Prompts findest du hier zu Prompt-Patterns in ChatGPT & Co.
Interessante Tools & Ressourcen zu den Parametern
- Hier geht zum OpenAI-Playground
- Hier findest du den Tokenizer von OpenAI
- Pro-Tipp: Hier gibt es ein Kalkulationstool für Tokens 8
- Hier kannst du, wenn du ein Konto im Playground hast, einen API-Key generieren
- Übersicht der verschiedenen GPT-Modelle und den Limitierung der Tokens
- Erweiterte Übersicht der Modelle (GPT und Anthropic) mit ihren jeweiligen Tokenbegrenzungen (Context-Window)
- Ein umfangreicher Guide zu Parametern bei Medium
- Mehr zur Temperature und Parametern
- Was ist Softmax und Temperature?
- Hier mein Link zu einem ChatGPT-Chat zu den Parametern
- in der API-Referenz von OpenAI findest du Details zu den Parametern
Wie hilfreich ist dieser Artikel für dich?
Noch ein Schritt, damit wir besser werden können: Bitte schreibe uns, was dir am Beitrag nicht gefallen hat.
Noch ein Schritt, damit wir besser werden können: Bitte schreibe uns, was dir am Beitrag nicht gefallen hat.
Vielen Dank für dein Feedback! Es hilft uns sehr weiter.

gar nicht hilfreich

weniger hilfreich

eher hilfreich

sehr hilfreich

ich habe ein anderes Thema gesucht