

Die Bewertung der Qualität von KI (Large Language Modellen) mit dem ELO-Score
Keine Artikel mehr verpassen? Jetzt Newsletter abonnieren »
Es gibt mehr als 150 unterschiedliche Large Language Modelle (LLMs), mit denen du dein Online Marketing verbessern könntest (die jeweils aktuelle Anzahl findest du hier: Chat Bot Arena auf dem Leaderboard). Ist das aktuelle Modell von ChatGPT wirklich das beste Modell oder einfach nur das bekannteste? Solltest du auf Claude.ai, Google Gemini oder das zur Zeit nur auf Umwegen in Europa verfügbare Llama 3.2 setzen? Wie gut ist die Qualität der einzelnen Modelle? Diese Fragen werden häufig mit dem ELO-Score beantwortet.
Im Folgenden stelle ich dir den ELO-Score kurz vor und zeige dir, wo du ihn für die einzelnen Modelle findest und welche Schwächen er noch hat.
Was ist der ELO-Score?
Der ELO-Score wurde von Arpad Elo entwickelt, um die Spielstärke von Schachspielenden objektiv zu messen. Jede Person erhält eine Punktzahl, die ihre Spielstärke repräsentiert. Die Idee ist, dass jemand Punkte gewinnt, wenn er oder sie gegen stärkere Gegner:innen gewinnt, und Punkte verliert, wenn er oder sie gegen schwächere Gegner:innen verliert. Dadurch passen sich die Punktzahlen kontinuierlich den tatsächlichen Fähigkeiten an. Der ELO-Score wird mittlerweile nicht nur im Schach, sondern auch in anderen Sportarten (z.B. Leistungsklassen im Tennis) und Online-Spielen verwendet.
Er hilft dabei, Teilnehmende mit ähnlicher Stärke zu finden und faire Wettbewerbe zu ermöglichen. Ein großer Vorteil des ELO-Scores ist seine dynamische Anpassungsfähigkeit. Ein Grund, warum er auch zur Bewertung von Large Language Modellen verwendet wird. Anders als statische Bewertungssysteme, die einmalige Ergebnisse liefern, passt sich der ELO-Score kontinuierlich an die aktuelle Leistung an. Dies macht ihn besonders geeignet für Umgebungen, in denen sich die Fähigkeiten der Teilnehmenden ständig ändern. Etwas, was wir zur Zeit im Bereich der LLM’s vorfinden.
Berechnungsformel und Anpassung
Wer mit Mathe auf Kriegsfuß steht, kann diesen Punkt auch überspringen. Das Konzept erschließt sich einem auch ohne die genaue Berechnung zu kennen bzw. zu können.
Die Formel des ELO-Scores lautet:
RA’ = RA + K x (S – EA)
RA’: neue Punktzahl
RA: aktuelle Punktzahl
K: Konstante
S: tatsächliche Ergebnis
EA: erwartete Ergebnis.
Die Berechnung des erwarteten Ergebnisses ergibt sich aus dem „Spielstärke-Unterschied“ RA-RB beider Spieler (A,B) vor dem Match.
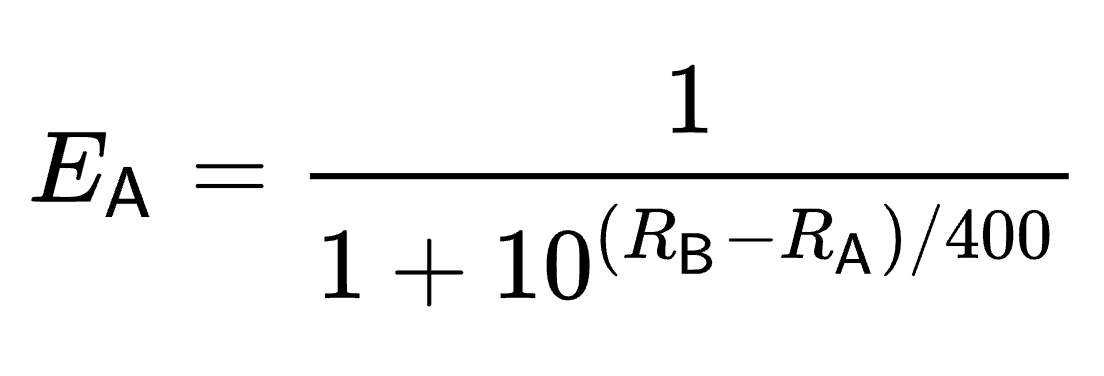
Wenn die Spielstärke RA größer als RB ist, wird der Exponent des 2. Teils im Nenner negativ. D.h. je größer der Unterschied, desto mehr tendiert der Teil 10^[(RA-RB)/400] gegen den Wert 0 und die Gewinnwahrscheinlichkeit (erwartetes Ergebnis) EA wird 1.
(Quelle: wikipedia.org)
Bei einem Sieg gegen stärkere Gegner:innen steigt die Punktzahl stärker, während sie bei einer Niederlage gegen schwächere Gegner:innen stärker fällt.
Mit dem ELO-Score KI bewerten
Bei der Erhebung des ELO-Scores werden LLMs relativ zueinander gemessen, basierend auf ihren Fähigkeiten, spezifische Aufgaben zu lösen oder auf Fragen zu antworten.
Eine Webseite, die den ELO-Score für LLMs erhebt und die häufig zitiert wird ist die Chatbot Arena – ein Service der Large Model Systems Organization (LMSYS Org). Die LMSYS ist eine offene Forschungsorganisation, die von Studierenden und Dozierenden der University of California, Berkeley, in Zusammenarbeit mit der Stanford University, der University of California, San Diego, und der Carnegie Mellon University gegründet wurde.
In der Chatbot Arena können Nutzer:innen selbst Fragen oder Aufgaben an KI-Modelle stellen, wie zum Beispiel: „Erkläre mir die Relativitätstheorie“ oder „Schreibe ein Gedicht über den Herbst“. Die Antworten der Modelle werden anonymisiert angezeigt und die Nutzer:innen entscheiden, welche Antwort qualitativ besser ist. Das Modell, das gewinnt, erhält Punkte, das unterlegene Modell verliert Punkte. So wird die Leistung der Modelle kontinuierlich bewertet.
Ein zentraler Aspekt der Chatbot Arena ist die Anonymität bei der Bewertung (Chatbot Arena Battle). Dadurch werden Verzerrungen durch Vorurteile oder Bekanntheit eines Modells vermieden. Nutzer:innen bewerten ausschließlich die Qualität der Antworten, was zu einer objektiveren Bewertung führt. Diese Vorgehensweise fördert Transparenz und Fairness im gesamten Bewertungsprozess und bietet eine klare Einschätzung der tatsächlichen Leistungsfähigkeit der Modelle.
Anonymer Battle-Ground auf der Chatbot Arena:

Es ist aber auch möglich, Modelle offen miteinander zu vergleichen. Die Ergebnisse fließen dann aber nicht in den ELO-Score mit ein. Wir nutzen gerne den offenen Vergleich, um gezielt einzelne Modelle zu Benchmarken. Unter “Parameter” sind hier auch Einstellungen für Fortgeschrittene möglich. So kannst du z.B. die Temperature oder den Top-P Wert einstellen.
Analysemöglichkeiten in der Chatbot Arena
Du kannst die Ergebnisse der Battles über den Menüpunkt „Leaderboard“ einsehen. In dieser Ansicht sind die Ergebnisse für alle Modelle basierend auf den aktuellen ELO-Scores absteigend nach Score aufgelistet. Hier findest du auch weitergehende Aufschlüsselungen z.B. anhand der Art der Prompts, die für den jeweiligen Vergleich eingegeben wurden und bekommst Einblicke in die Stärken und Schwächen einzelner Modelle, z.B. für Mathe, im Bereich der Softwareprogrammierung oder für einzelne Sprachräume (Englisch, Deutsch, Chinesisch etc.).
Ergebnis-Übersicht und Ranking: Leaderboard
Herausforderungen und Grenzen der ELO-basierten Bewertung
Obwohl der ELO-Score eine innovative Methode zur Bewertung von KI-Modellen darstellt, gibt es auch Kritikpunkte.
Ein zentrales Problem ist die Abhängigkeit von der Qualität und Komplexität der gestellten Fragen (Prompts). Wenn einfache Fragen bzw. Aufgaben gestellt werden, schneiden auch schwächere Modelle gut ab, was eine verzerrte Darstellung der tatsächlichen Fähigkeiten der Modelle zur Folge haben kann. Komplexere Fragen offenbaren größere Leistungsunterschiede. Eine Lösung wäre, standardisierte Testsätze einzuführen.
Darüber hinaus erfordert das ELO-Scoring-System eine relativ hohe Anzahl an Battles, um stabile und aussagekräftige Ergebnisse zu erhalten. Insbesondere bei der Verwendung von Filterfunktionen zur Eingrenzung auf bestimmte Modellgruppen oder Sprachräume entstehen oft geringe Fallzahlen, was die Vergleichbarkeit erschwert. Ähnliches gilt für neue Modelle, die zunächst eine geringe Anzahl an Battles und somit recht schwankende ELO-Scores (Anfangsvarianz) aufweisen.
Subjektivität und Repräsentativität der Nutzerbewertungen
Da die Bewertungen in der Chatbot Arena auf den Präferenzen der Nutzer:innen basieren, besteht die Gefahr subjektiver oder auch kultureller Verzerrungen, wenn überwiegend eine bestimmte Bevölkerungsgruppe oder Mitglieder eines Kulturraums die Fragen stellen und die Ergebnisse bewerten. Ähnlich wie in der Marktforschung erhalten wir ggf. schon bei der Auswahl der Probanden Biases. Auch werden wir immer vertrauter mit LLMs und dadurch womöglich “eingefahrener”, was unsere Prompts (Eingabeaufforderungen) anbelangt. D.h. gängigere Fragestellungen werden häufiger vorkommen als außergewöhnliche Ansätze, Fragen zu stellen. Die Varianz der Aufgaben könnte somit über die Zeit abnehmen.
Diesen Schwächen stehen aber auch zahlreiche Vorteile der Bewertung mittels ELO-Score gegenüber: Die Methode ist in der Lage, eine Vielzahl von Modellen gleichzeitig zu bewerten. Neue Modelle können schnell integriert werden, und durch die kontinuierliche Anpassung der ELO-Scores bleibt die Bewertung aktuell. Durch die Nutzung des ELO-Scores passen sich die Punktzahlen der Modelle kontinuierlich an ihre aktuelle Leistung an. So bleibt die Bewertung immer präzise und aktuell. Die Nutzer:innen haben die Möglichkeit, Fragen aus unterschiedlichen Themenbereichen zu stellen. Dies gewährleistet eine umfassende Bewertung der Modelle über eine breite Palette von Fähigkeiten hinweg.
Vergleich zwischen ELO-Score und alternativen Methoden
Neben dem ELO-Score gibt es weitere Ansätze, um die Leistung von KI-Modellen zu bewerten. Jede Methode hat spezifische Stärken und Schwächen und ist je nach Anwendungsszenario unterschiedlich geeignet.
Statische Benchmarks arbeiten mit vordefinierten Aufgaben oder Testsätzen, die jedes Modell durchlaufen muss. Sie bieten den Vorteil, dass die Ergebnisse reproduzierbarer und objektiv vergleichbarer sind (wenngleich auch die LLMs selbst ja bei gleichen Aufgaben eine gewisse Varianz der Antworten haben, Stichwort „Temperature“). Der Nachteil ist jedoch, dass Modelle oft speziell auf diese Tests hin optimiert werden können, was nicht immer ihre allgemeine Leistungsfähigkeit in realen Szenarien widerspiegelt.
Der ELO-Score dagegen ermöglicht eine dynamische Bewertung basierend auf Echtzeit-Nutzerbewertungen. Statt vordefinierten Aufgaben stehen Modelle in einem breiteren Kontext im direkten Vergleich, was eine kontinuierliche Anpassung der Bewertung ermöglicht und die tatsächliche Leistung im Vergleich zu anderen Modellen besser abbildet.
Komplett freie, menschliche Evaluationen berücksichtigen subjektive Kriterien wie Kreativität oder Stil, die standardisierte Metriken, wie „hat gewonnen“, „hat verloren“ oft nicht erfassen. Besonders bei komplexen oder kreativen Aufgaben liefern sie wertvolle qualitative Informationen. Der Nachteil sind die hohen Kosten und der Zeitaufwand, insbesondere bei vielen Modellen.
Der ELO-Score kombiniert qualitative menschliche Bewertungen mit einer objektiven Skala. Nutzer:innen bewerten die Antworten, und diese Rückmeldungen fließen direkt in die kontinuierliche Bewertung ein. Dadurch wird eine Kombination aus qualitativen und quantitativen Bewertungen erreicht.
Aufgabenbasierte Evaluationen testen Modelle in spezifischen, realen Szenarien und sind besonders praxisnah. Ihr Nachteil liegt in der eingeschränkten Übertragbarkeit, da unterschiedliche Modelle auf unterschiedliche Aufgaben spezialisiert sein können. Dies erschwert den Vergleich.
Der ELO-Score schafft hier Abhilfe, da alle Modelle ähnliche Aufgaben bearbeiten und die Nutzer:innen die Antworten direkt vergleichen. Dadurch wird eine Vergleichbarkeit zwischen verschiedenen Modellen unabhängig von deren Spezialisierungen ermöglicht.
Integration verschiedener Ansätze auf Artificial Analysis
Die Kombination verschiedener Bewertungsmethoden bringt häufig eine präzisere Einschätzung der Leistung von KI-Modellen. Auch geht es bei KI nicht nur um die Qualität der Antworten, sondern auch um die benötigte Rechenleistung, um Antworten zu generieren, oder der Schnelligkeit der Antwort. Eine Webseite, die einen Überblick über die verschiedenen Ansätze gibt und Testergebnisse liefert, ist artificialanalysis.ai.
Test-Übersicht für ELO-Scores und weitere Qualitätsmerkmale: Artificial Analysis
https://artificialanalysis.ai/
Fazit
Der ELO-Score bietet dir ein dynamisches und kontinuierliches System zur Bewertung von Large Language Modellen (LLMs).
Im Gegensatz zu statischen Benchmarks oder spezifischen, aufgabenbasierten Tests bietet der ELO-Score den Vorteil, dass er die Leistungsfähigkeit der Modelle im direkten Vergleich misst und sich flexibel an ihre sich verändernden Fähigkeiten anpasst. Er zeigt dir eine faire und fortlaufende Bewertung der Large Language Modelle anhand realer Nutzerrückmeldungen.
Trotz einiger Herausforderungen, wie der Abhängigkeit von der Qualität der Prompts oder den potenziellen Verzerrungen durch Nutzerpräferenzen, bietet das System dir wertvolle Einblicke in die tatsächliche Leistung von LLMs in der Praxis.
Es ist vor allem für dich und/oder dein Unternehmen hilfreich, wenn du in der schnelllebigen Welt der KI-Landschaft eine schnelle erste Orientierung möchtest. Er liefert eine aktuelle Übersicht der Stärken und Schwächen der Modelle – von ChatGPT über Claude.ai bis hin zu Google Gemini oder Llama 3.2. Er hilft die vielleicht 2 bis 3 Modelle zu identifizieren, die du dann selbst vor dem Hintergrund deiner konkreten Herausforderungen (im Unternehmen) weiter evaluieren möchtest.
Wie hilfreich ist dieser Artikel für dich?
Noch ein Schritt, damit wir besser werden können: Bitte schreibe uns, was dir am Beitrag nicht gefallen hat.
Noch ein Schritt, damit wir besser werden können: Bitte schreibe uns, was dir am Beitrag nicht gefallen hat.
Vielen Dank für dein Feedback! Es hilft uns sehr weiter.
gar nicht hilfreich
weniger hilfreich
eher hilfreich
sehr hilfreich
ich habe ein anderes Thema gesucht